1. 데이터셋 준비
이번 데이터셋은 다양한 유형이 있는 데이터 셋으로 준비했습니다. 쇼핑몰별 고객들에 관한 데이터셋입니다.
https://www.kaggle.com/datasets/mehmettahiraslan/customer-shopping-dataset?resource=download
Customer Shopping Dataset - Retail Sales Data
Exploring Market Basket Analysis in Istanbul Retail Data
www.kaggle.com
2. 데이터셋 살펴보기
데이터셋은 총 99457행으로 이루어져 있으며, 칼럼은 10개로 숫자형 칼럼과 범주형 칼럼이 섞여있습니다.
대표적인 숫자형 컬럼은 나이와, 물건구매수량, 물건 가격이며, 범주형 칼럼으로는 성별과, 물건 결제 방법, 구매한 쇼핑몰에 관한 정보로 이루어져 있습니다.

2024.08.21 - [데이터 공부/데이터 시각화] - [데이터 시각화] Spotfire로 데이터 시각화 해보기 - 데이터의 종류 살펴보기
[데이터 시각화] Spotfire로 데이터 시각화 해보기 - 데이터의 종류 살펴보기
데이터는 다양한 형태로 존재하며, 이를 이해하기 위해 데이터의 유형을 분류하는 것이 중요합니다. 데이터의 주요 유형에는 연속형 자료, 이산형 자료, 순위형 자료, 명목형 자료가 있습니다.
informyun.com
2-1. 숫자형 Vs 숫자형
두 숫자형 변수 간의 관계를 분석하는 것으로, 주로 연속적인 값들이므로 상관관계나 회귀 분석을 통해 변수 간의 연관성을 볼 수 있습니다. 지금 같은 데이터에서는 나이를 기준으로 가설을 세운다면, 나이가 많을수록 지불하는 비용이 높을 것인가에 대한 가설을 세울 수 있습니다.

2-2. 숫자형 Vs 범주형
숫자형과 범주형을 비교할 경우, 범주형은 순서의 개념이 없으며 주로 문자형태(string)를 나타냅니다. 날짜와 시간도 범주형 데이터에 속합니다. 아래와 같이 "나이"가 종속변수인 상태에서 각각의 독립변수와 어떤 것이 가장 관련이 높은지 확인할 수 있습니다.

2-3. 범주형 Vs 범주형
범주형과 범주형 데이터의 연관성을 분석할때는 일반적으로 카이제곱 검정이 사용됩니다.(Spotfire에서 지원)
카이제곱 검정이란 두 범주형 변수간에 독립적인지 아니면 서로 연관성이 있는지를 검정합니다.
[ 카이제곱 검정 ]
- 두 변수의 교차표를 작성하여 각 범주의 빈도를 계산합니다.
- 각 셀에서 기대되는 빈도를 계산합니다. 이는 두 변수 간에 독립적일 경우 예상되는 빈도입니다.
- 관찰된 빈도와 기대되는 빈도의 차이를 이용해 카이제곱 통계량을 계산합니다.
- 이 통계량을 사용해 귀무가설을 검정합니다. 귀무가설은 보통 두 변수 간에 독립적이라는 가정입니다.

3. 데이터 유형에 따른 분석기법 차이

Spotfire 에서 해당 5가지 기능을 제공하며, Data Relationship에서 직접 선택해서 사용할 수 있습니다. Linear Regression을 누르면, 해당 분석방법은 숫자형 Vs 숫자형 데이터 이므로 종속변수 Y와 독립변수 X에 숫자형 칼럼만 표시됩니다.
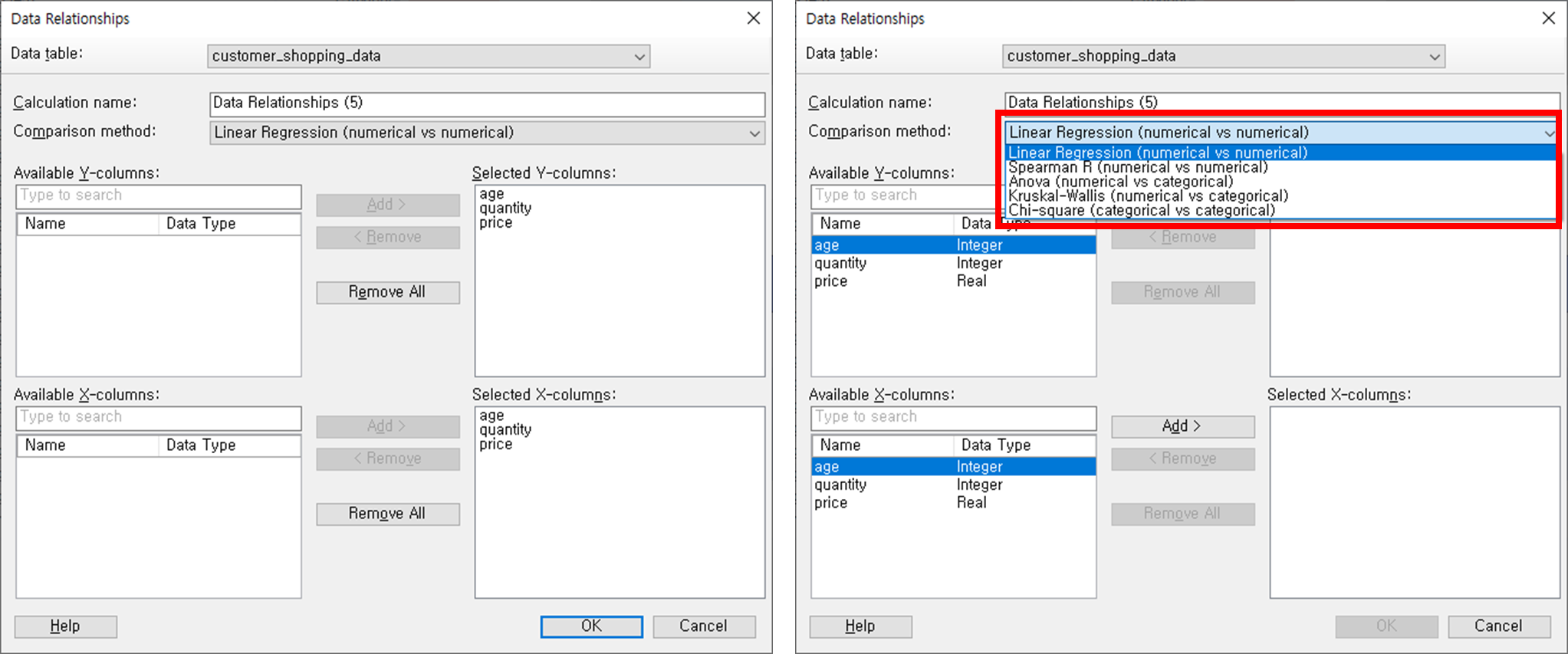

2024.08.21 - [데이터 공부/통계 공부] - [데이터 시각화] Spotfire로 데이터 시각화 해보기 - 상관계수와 결정계수 이론 살펴보기
[데이터 시각화] Spotfire로 데이터 시각화 해보기 - 상관계수와 결정계수 이론 살펴보기
상관계수와 결정계수는 데이터 분석과 통계학에서 중요한 개념으로, 두 변수 간의 관계를 이해하고 모델의 설명력을 평가하는 데 사용됩니다. 이 포스팅에서는 상관계수와 결정계수의 정의, 계
informyun.com
'데이터 공부 > 데이터 시각화' 카테고리의 다른 글
| [데이터 시각화] Spotfire로 데이터 시각화 해보기 - Line Similarity (라인 유사성), Trellis 활용 (0) | 2024.09.01 |
|---|---|
| [데이터 시각화] Spotfire로 데이터 시각화 해보기 - Dendrogram 숫자형 Vs 숫자형 3. (0) | 2024.08.30 |
| [데이터 시각화] Spotfire로 데이터 시각화 해보기 - Heat map 숫자형 Vs 숫자형 2. (0) | 2024.08.29 |
| [데이터 시각화] Spotfire로 데이터 시각화 해보기 - 선형회귀 (Linear Regression) 숫자형 Vs 숫자형 1. (1) | 2024.08.28 |
| [데이터 시각화] Spotfire로 데이터 시각화 해보기 - Box plot 실습 (0) | 2024.08.27 |




